Brothers in Alms: Bernie & Trump
Have two politicians ever despised one another more than Bernie Sanders and Donald Trump? Not likely. And yet as much as these two mortal combatants despise one another they do share a few things. As of September 2019 of the 3 million donations given to either Sanders or Trump 108 donors gave to both.
This project is really an excuse to try out Google’s BigQuery. It is cloud based SQL where one can store and analyze terabytes of data almost instantaneously and almost for free.
There were 4 steps to this project:
1. Download the Federal Election Data into a CSV spreadsheet and do some rudimentary cleaning there.
2. Further clean the data in R.
3. Mutate and filter the data using Google’s BigQuery SQL.
4. Graph it in Neo4J
Step 1: MAKING A SPREADSHEET OF THE DATA.
Open the FEC file from this page:
https://www.fec.gov/data/committee/C00580100/?cycle=2016&tab=filings
Click on the download csv button. NOTE the label is one month after the data. 5/1 to 5/30 file is labeled July.
Locate file and rename it June.
Open file in Libre or whatever your favorite spreadsheet program is. The top of the sheet is littered with extraneous detail. Delete these rows.
There are many more columns than are of any use to us . Open a new spreadsheet and paste the column headings below into it, then copy and paste the relevant columns from the original FEC file into this new spreadsheet. In this way we preserve the original data file, drop the extraneous , and fix the col names.
I confess I do not recall now why but I remember the best way to do this was to paste right on top of the column name and then when done, inserting a new blank row, and re- inserting the col names again.
| name_last | name_first | address | city | state | zip | amnt | employer | occupation |
|---|
We will be stacking all of our data sets together so it is critical that the columns are always in this order.
Save this sheet as something like Sanders_June_19_Select.csv
Step 2: CLEAN THE DATA IN R
Load tidyverse and Lubridate
library(tidyverse)
library(lubridate)
Next run these steps over the file for each month for each candidate.
Sanders_Oct_Nov_16_Select <- read_csv(“Sanders_Oct_Nov_16_Select.csv”)
View(Sanders_Oct_Nov_16_Select)
Sanders_Oct_Nov_16_Select$zip <-as.integer(gsub(‘[a-zA-Z]’, ”,Sanders_Oct_Nov_16_Select$zip))
Sanders_Oct_Nov_16_Select$amnt <- round(Sanders_Oct_Nov_16_Select$amnt)
Sanders_Oct_Nov_16_Select$date <- as.Date(as.character(Sanders_Oct_Nov_16_Select$date) , “%Y%m%d”)
dim(Sanders_Oct_Nov_16_Select)
Sanders_Oct_Nov_16_Select <- na.omit(na.omit(Sanders_Oct_Nov_16_Select, cols=c(“name_last”,”address”,”city”,”state”,”zip”,”amnt”,”date”)))
dim(Sanders_Oct_Nov_16_Select)
write_csv(Sanders_Oct_Nov_16_Select , “Sanders_Oct_Nov_16_Select_A.csv”)
Step 3: Mutate and filter the data using Google’s BigQuery SQL.
The first thing to do is to upload each file to Google’s cloud Storage. Once every file is uploaded to Google Cloud Storage from within BigQuery create a dataset.
* * *
A frustration saving note about Google’s BigQuery.
Upload your data to Google Cloud Storage and import it into BigQuery from there.
Bewilderingly, the name that Google Cloud Storage assigns needs to be tweaked to run in BigQuery.
This is the name assigned by Google Cloud Storage:
jf11579campaigncontributions:obama.Sanders_2016_through_Sept_2019_2
Note the full colon, change that to a decimal.
And then enclose the entire name between backticks NOT single quote marks.
It needs to look like this:
`jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
* * *
SELECT *
FROM `jf11579campaigncontributions.test.Test_bernie`
UNION ALL
SELECT *
FROM `jf11579campaigncontributions.test.Test_trump`
Once all of the files are imported into BigQuery the next thing to do is to join them all into a single table. I chose to separately join all of the Trump files together into one file and the Sanders files together in a separate file. Later I joined these two together.
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Jan_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Feb_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_March_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_April_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_May_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_June_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_July_16_Select_BB`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Aug_16_Select`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Sept_16_Select`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Oct_16_Select`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Oct_Nov_16_Select`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_Jan_Feb_March_19_C`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_April_May_June_C`
UNION ALL
SELECT *
FROM
`jf11579campaigncontributions.obama.Trump_July_Aug_Sept_19_Select_C`
Let us take a look at the table. The Trump file has 1.3 million rows
SELECT *
FROM
`jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
Limit 3
| name_last | name_first | address | city | state | zip | amnt | employer | occupation | date | candidate |
|---|---|---|---|---|---|---|---|---|---|---|
| Carson | Richard | POB 123 | APO | AA | 34022 | 300 | U.S. DEPARTMENT OF STATE | MANAGEMENT OFFICER | 2016-03-03 | Trump |
| Carson | Richard | POB 123 | APO | AA | 34022 | 49 | U.S. DEPARTMENT OF STATE | MANAGEMENT OFFICER | 2016-03-10 | Trump |
| Cool | Dwayne | POB 456 | FPO | AE | 9645 | 50 | UNIVERSITY OF TENNESSEE | USN ELECTRONICS TECHNICIAN | 2016-03-17 | Trump |
The Sanders donation data has 2million rows.
SELECT *
FROM
`jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
Limit 3
Here we join Trump and Sanders
SELECT *
FROM `jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
UNION ALL
SELECT *
FROM `jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
But before we get into the weeds with actual data let us have a run through with a practice data set first.
Here is a practice Sanders test data
| name_first | name_last | address | zip | state | amount | candidate |
|---|---|---|---|---|---|---|
| ann | adams | 1 A | 11111 | NY | 5 | bernie |
| agatha | boxer | 2 B | 11111 | NY | 10 | bernie |
| attilda | carlson | 3 C | 11222 | CT | 15 | bernie |
| annabelle | davidson | 4 d | 12345 | NJ | 15 | bernie |
| alexa | ericson | 5 fifith | 12566 | NJ | 10 | bernie |
| amelia | frazer | 6 F | 11111 | NJ | 10 | bernie |
| abigail | grant | 7 seventy | 11510 | NJ | 5 | bernie |
| bill | gunter | 1 first | 11111 | NY | 20 | bernie |
| amy | harris | 8 H | 11545 | CT | 10 | bernie |
| ben | harris | 2 second | 21212 | NJ | 25 | bernie |
| athena | izzo | 9 I | 11579 | NY | 15 | bernie |
| angela | james | 10J | 11579 | NY | 20 | bernie |
And here is the Trump test data
| name_first | name_last | address | zip | state | amount | candidate |
|---|---|---|---|---|---|---|
| ballontine | adams | 2 B | 55555 | AL | 20 | trump |
| bain | boxer | 4 A | 66666 | WY | 5 | trump |
| brian | frazer | 5 fifth | 11111 | BY | 10 | trump |
| babson | gomez | 1 A | 11111 | NY | 5 | trump |
| bill | gunter | 1 first | 11111 | NY | 20 | trump |
| ben | harris | 2 second | 21212 | NJ | 25 | trump |
| baker | hill | 3 B | 11579 | NY | 10 | trump |
| bob | inez | 3 third | 31313 | VT | 30 | trump |
| athena | izzo | 9 I | 11579 | NY | 15 | trump |
| angela | james | 10J | 11579 | NY | 20 | trump |
| brad | james | 4 fourth | 11222 | CT | 5 | trump |
Again, upload them to Google cloud then move them into BigQuery by creating a datasets. Once that is done join the two datasets.
SELECT *
FROM `jf11579campaigncontributions.test.Test_bernie`
UNION ALL
SELECT *
FROM `jf11579campaigncontributions.test.Test_trump`
Here is the combined Sanders and Trump test data.
| name_first | name_last | address | zip | state | amount | candidate |
|---|---|---|---|---|---|---|
| attilda | carlson | 3 C | 11222 | CT | 15 | bernie |
| amy | harris | 8 H | 11545 | CT | 10 | bernie |
| annabelle | davidson | 4 d | 12345 | NJ | 15 | bernie |
| alexa | ericson | 5 fifith | 12566 | NJ | 10 | bernie |
| amelia | frazer | 6 F | 11111 | NJ | 10 | bernie |
| abigail | grant | 7 seventy | 11510 | NJ | 5 | bernie |
| ben | harris | 2 second | 21212 | NJ | 25 | bernie |
| ann | adams | 1 A | 11111 | NY | 5 | bernie |
| agatha | boxer | 2 B | 11111 | NY | 10 | bernie |
| athena | izzo | 9 I | 11579 | NY | 15 | bernie |
| angela | james | 10J | 11579 | NY | 20 | bernie |
| bill | gunter | 1 first | 11111 | NY | 20 | bernie |
| ballontine | adams | 2 B | 55555 | AL | 20 | trump |
| baker | hill | 3 B | 11579 | NY | 10 | trump |
| athena | izzo | 9 I | 11579 | NY | 15 | trump |
| angela | james | 10J | 11579 | NY | 20 | trump |
| bob | inez | 3 third | 31313 | VT | 30 | trump |
| bill | gunter | 1 first | 11111 | NY | 20 | trump |
| brian | frazer | 5 fifth | 11111 | BY | 10 | trump |
| babson | gomez | 1 A | 11111 | NY | 5 | trump |
| bain | boxer | 4 A | 66666 | WY | 5 | trump |
| brad | james | 4 fourth | 11222 | CT | 5 | trump |
| ben | harris | 2 second | 21212 | NJ | 25 | trump |
Here is a not small difference between SQL and BigQuery’s version of SQL. Big Query only offers –as of Jan 2020–a single version of filtering by intersection: INTERSECT DISTINCT. It is a combined GROUP BY and INNER JOIN.
Let us look for the same last name that appear in both Sander’s and Trump’s list of donors:
SELECT name_last
FROM `jf11579campaigncontributions.test.Test_bernie`
INTERSECT DISTINCT
SELECT name_last
FROM `jf11579campaigncontributions.test.Test_trump`
This returns 7 names:
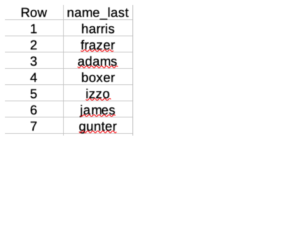
A quick glance at the Sanders Trump joined table shows that there are more than one harris and frazer so which harris and frazer contributed to both candidates?
Let us add more criteria, name_first:
SELECT name_last, name_first
FROM `jf11579campaigncontributions.test.Test_bernie`
INTERSECT DISTINCT
SELECT name_last, name_first
FROM `jf11579campaigncontributions.test.Test_trump`
Our results drop from 7 to 4.
And if we add in address our results are unchanged.

And if we add in address our results are unchanged.
SELECT name_last, name_first,address
FROM `jf11579campaigncontributions.test.Test_bernie`
INTERSECT DISTINCT
SELECT name_last, name_first, address
FROM `jf11579campaigncontributions.test.Test_trump`
Now back to our real world data.
MOST unfortunately our real world data do not work out so simply.
Let us finally compare the two tables:
SELECT name_last
FROM `jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
INTERSECT DISTINCT
SELECT name_last
FROM `jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
This returns 1991 names. But this is not meaningful. We are only looking at names in common so far, not people in common. Let us add name_first to the criteria. This drops us down to 551 rows.
SELECT name_last , name_first
FROM `jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
INTERSECT DISTINCT
SELECT name_last, name_first
FROM `jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
Heartbreakingly , if we add address we get 0 results.
SELECT name_last , name_first, address
FROM `jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
INTERSECT DISTINCT
SELECT name_last, name_first, address
FROM `jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
Interestingly, if we search only on matching addresses we get 11. Apparently there are 11 households where different people residing under the same roof where one donated for Sanders while the other donated for Trump. Meals must be quiet there.
SELECT address
FROM `jf11579campaigncontributions.obama.Sanders_2016_through_Sept_2019_2`
INTERSECT DISTINCT
SELECT address
FROM `jf11579campaigncontributions.obama.TRUMP_2016_thru_Sept_19_B`
But back to our question. If we search for matches on name_last and name_first we get 551 matches. If we add zip it drops to 3.
If we search name_last and name_first and state we get back 108
It would be nice if we could match on all eight criteria (name_last, name_first, address, city, state, zip, employer) but we cannot . Or maybe we can and the truth of the matter is that there are zero people who gave to both Trump and Sanders but out of 3 million donors I am guessing this is not the case.
If you have never donated online to a candidate, which is where this data comes from , one has to enter quite a bit of detail about yourself including employer and occupation. People are entering this themselves so the data should be accurate. It is my guess that people would prefer to give anonymously and resent having to disclose this much detail about themselves and so somewhat sabotage the data but at this point , this is only a guess.
Another possibility may be BigQuery’s limited JOIN capability. INTERSECT DISTINCT which is an inner join + group by might be giving us lower results than if we had done this in SQL. In any event next we will graph it using Neo4J
Step 4. GRAPH IN NEO4J
Step one clear out any old data.
MATCH (n)
DETACH DELETE n
Step two load the dat and create the nodes.
LOAD CSV WITH HEADERS FROM ‘file:///Bernie_Trump_108_Indexed.csv’ AS csvDATA
MERGE (candidateTrump:CandidateTrump{candidate:”trump”})
MERGE (candidateSanders:CandidateSanders{candidate:”sanders”})
MERGE (donor:Donor {LastName: csvDATA.name_last, FirstName: csvDATA.name_first, FullName: csvDATA.full_name, State: csvDATA.state})
FOREACH (_ IN case when csvDATA.candidate = ‘trump’ then [1] else [] end|
CREATE (donor)-[donorRel:DONATED]->(candidateTrump)
)
FOREACH (_ IN case when csvDATA.candidate = ‘sanders’ then [1] else [] end|
CREATE (donor)-[donorRel:DONATED]->(candidateSanders)
)
Step three graph.
MATCH p = (d:Donor)-[r:DONATED]->()
RETURN p


Recent Comments