A Year’s Worth of Google Searches (Python, Google Trends & Correlate)
How many sex assault crimes go unreported?
We will use data from Google TRENDS to try and get an idea of how prevalent sex crimes are . This is Part 1 of a two part project. In Part 1 we gather the daily and hourly search data for various terms that we think are related to RAPE. Part 2 will be comparing our data with govt sex crimes data. If there are discrepancies perhaps they will give us an idea of the under reporting.
This project was inspired by Seth Stephens-Davidowitz’s book EVERYBODY LIES. Seth points out that while we might lie to ourselves , our significant others, our spouses, and our children, the one place we never lie is the Google search box. We only type in there what is honestly on our minds. With that in mind, we will go through aggregated Google search queries believing that people who have been sexually assaulted , while they may never tell anyone, are telling Google.
I enter the term RAPE into TRENDS and set it for the past 1 hour and here is the graph. If any part of our starting assumption is correct, the specificity is upsetting . On this Sunday morning at 11:27am here is the search activity for the term RAPE in the past 60 minutes. Of course , not everyone searching RAPE has been assaulted but by comparing related terms we might be able to bolster our hunch.

The rub is that the longest time span Google reports hourly data for is 7 days so one needs a work around to get one year’s worth of data. That work around is PyTrends (https://pypi.org/project/pytrends/ ). I cobbled together various implementations of it that I found on the web (https://github.com/GeneralMills/pytrends/blob/master/examples/example.py, https://stackoverflow.com/questions/48246083/how-do-i-work-with-the-results-of-pytrends) . No single one worked for me. I think there is a cat and mouse aspect to this. I guess that Google is continually revising TRENDS and that knocks-out scripts like these. But for now it works.
Import these packages into Python:


“hl=’en-US’ is the language we will search in, in our case that is obviously enough, US English.
“tz=360” is the Central Time zone of the US. Since we are searching the entire US this seems a fair setting.
“Kw_list” are are the terms we will search for . Five terms are the max per iteration.
Next is where the magic happens.

Last things first, those two error messages. Error code 500 means something went wrong at Google’s end. When one runs the code multiple times sometimes it fails completely with the same error code, sometimes it runs but with a dozen Error Code 500’s . Two Errors was as good as I could get. There are 8,760 hours in a year. The best we could get was 8281 observations. 479 missing. 5%. It is what it is.
Specify Start and End dates; cat is for category if one wishes to narrow the search to, for example, Experimental & Industrial Music one would enter cat= 1022 ( the full list can be found at https://github.com/pat310/google-trends-api/wiki/Google-Trends-Categories), 0 is all categories; gprop is Google Property do you want to search in Pictures , News, etc.? Blank is the default and it will search everything.
Now I have to amend something. The search above I was unable to prefix with a name and save it as dataframe. I could run the code but I could not save it as a data frame I have no explanation . Fortunately though if I altered my criteria and searched for only 3 month periods I was able to save the output as as df .
Same result but for only the first quarter of the year. We did this for all four quarters then stitched them together.

The output looks like this:

We exported the four resulting dataframes as csv and imported them into R where the rest of this project continues
The R packages we will need:

We import each quarter of the PyTrends output and save them as First,Second, Third,and Fourth, then bind them together and call it Year:

Next we have some data cleaning-up to do. Here is how our data set starts.

We will be looking how each day of the week influences the number of searches so we will need to add weekday as a variable

Similarly we will compare searches by the time of day so we will need to add Time as a variable

Next let’s substring to isolate just the hour since will be comparing hours.

Now we are ready to graph.
The procedure will be to group_by one of the variables ,e.g. Weekday, and then to plot.
As a safety procedure , I use a neanderthal iteration control system of continually revising the name of my dataset in case something goes awry so you might notice the dataset is called Year2 and not simply Year.
Here we create a dataset called WeekdayRapeTotals by summing up all of the searches for RAPE that occurred on each day of the week for the year 2018.

The output:

We are finally ready for our first graph.

GROAN. The columns are in alphabetical order . Lets correct that.

Now let us re-plot that:

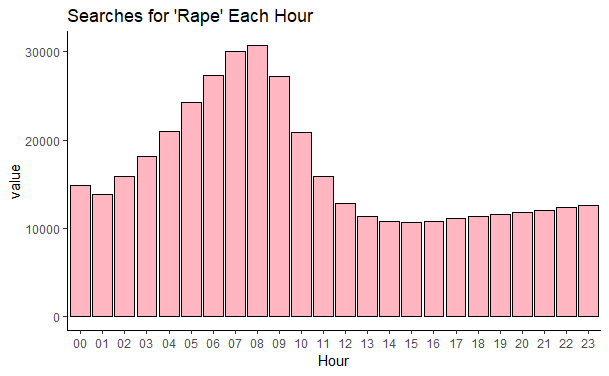
I am surprised that there is so little difference for the number of searches for RAPE between the days.
Now let us do a similar thing but look at the HOURLY level:
And the graphing code


And the hourly graph :





Eyeballing graphs is all well and fine but lets run a correlation too.
Our data set has some extraneous columns so lets extract just the relevant ones.

Then we run:

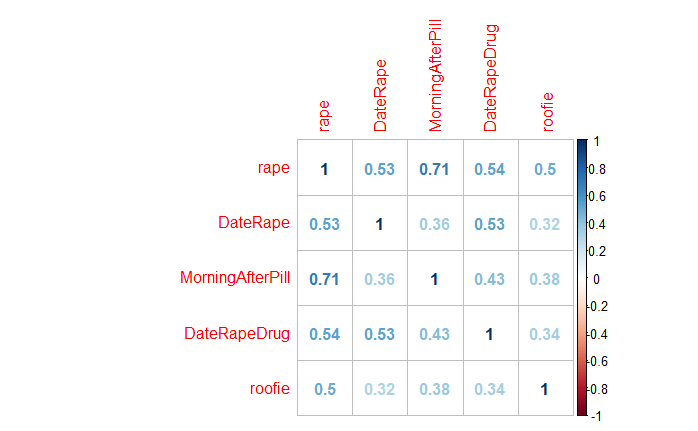
My first reaction is that except for RAPE/MorningAfterPill the correlations are not significant. But this needs to be examined more and perhaps maybe even 0.36 may prove to be significant. This is important because we are investigating whether there is any significance to what people search. How to put this? If it was shown that people search for the individual members of baseball team at about the same level then it would seem a fair assumption to think that these searches are related by the same interest or shared interest and not likely to be unconnected. The searches of the NY Mets baseball team players are done by people who have an interest in the NY Mets. Now regarding Sexual assault, if it turns out that we see similar correlation levels between our Sexual assault search terms as we find among pro baseball players then we may think our terms are realted
Or in case anyone prefers pies to numbers:

Thoughts so far?
The access to the data is amazing but how to interpret it will take some experimination. Perhaps compare these correlations with another set of words that we think would be related like the members of professional sports team.
Not mentioned before is Google Correlate. Enter a word and it tells you what words have a similar search history. This could mean that anytime someone looks up Term A they also search Term B or it could mean that the searches are searched with equal frequency but by different people. In anyevent, in looking for terms correlated to RAPE I tried to Google Correlate. No luck. Not one of our words had any other words that correlated with it. I find this hard to believe and suspect that it has something to do with that the nature of our group of words was sexual violence and Google is blocking that.
Once we are confident in our interpretation of the TRENDS data then we can begin to compare it to government crime statistics and maybe anomalies can point the way to a better grasp of how prevalent sexual assault is in the US.
Recent Comments